Product
Distracted driving is one of the leading causes of automobile accidents that can lead to damages that even money cannot replace. At Soteria we provide a new way to prevent this risk and introduce a revolutionary end-to-end product.
Watch the video below to see the product in action. Notice how the device detects distracted driving and notifies the driver in real-time!
How It Works
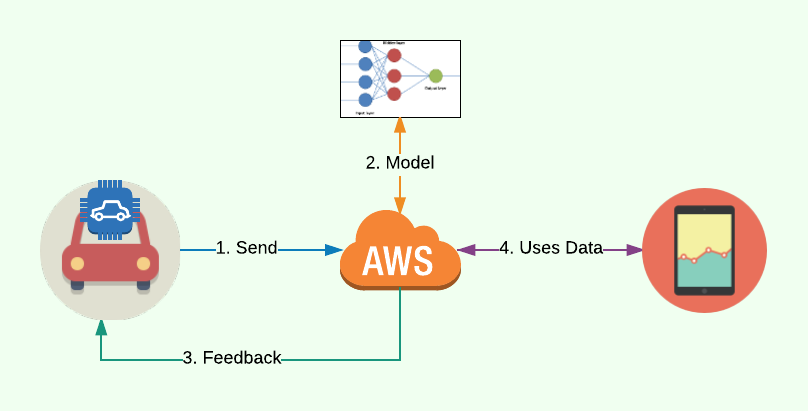
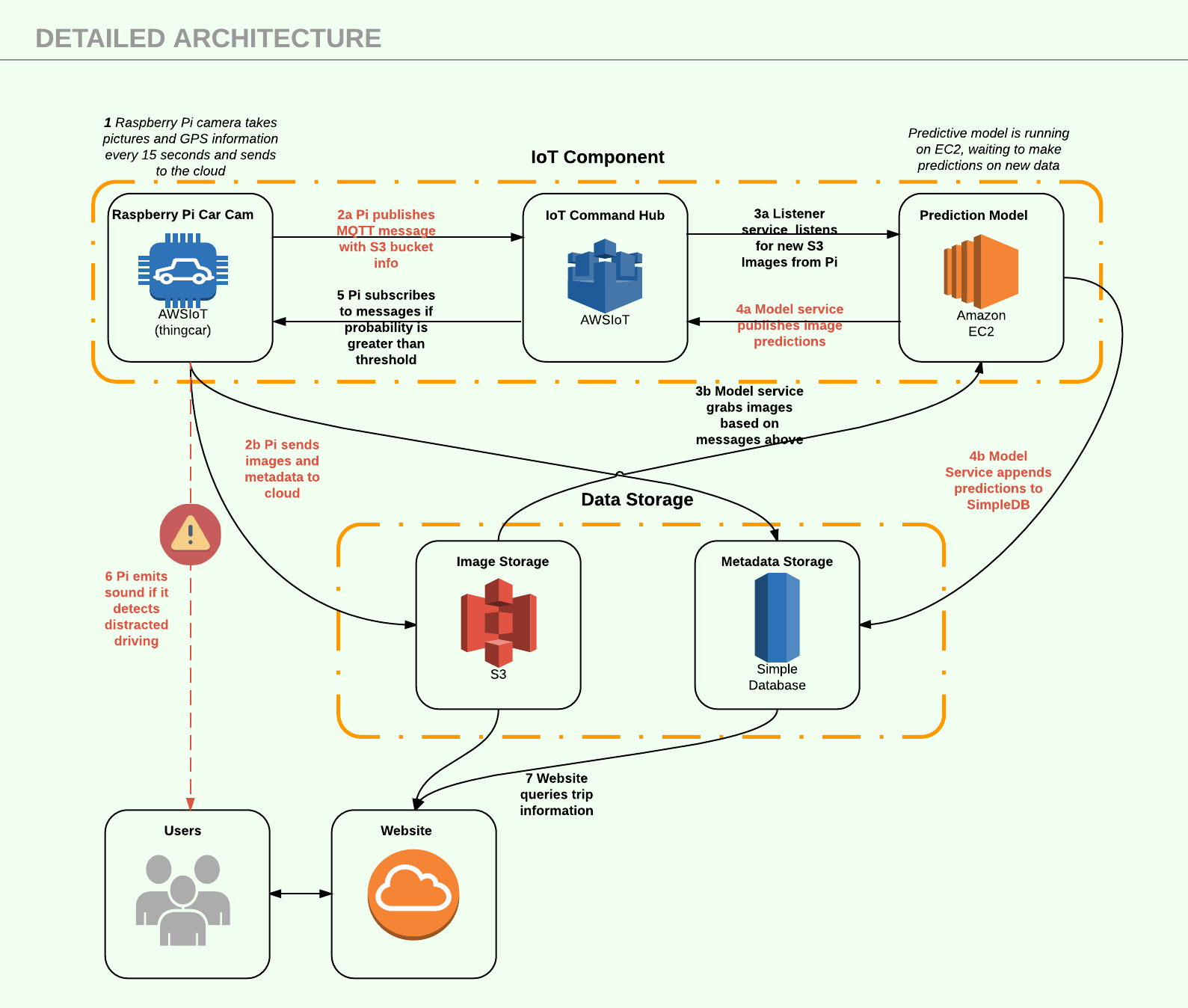
Soteria uses combination of the internet of things (IoT) and machine learning to detect distracted driving. The IoT component consists of a Raspberry Pi unit connected to the cloud while the machine learning component is a convolutional neural network (CNN).
To truly combat the issue of distracted driving, Soteria provides users feedback while they are driving. Soteria is the first product that attempts to prevent distracted driving in a proactive manner. We do so by placing a small, in-car camera in the user's vehicle.

By placing a device in the user's vehicle, we are able to capture images of the driver over fixed intervals (e.g. every 15 seconds). Images and GPS coordinates are then passed to our cloud servers which are running our state-of-the-art model. Should the model detect distracted driving, the driver will be notified via a chime through the car stereo system (similar to how modern cars warn drivers if the seatbelt is not fastened). Click play below to hear the warning chime.
Product Architecture
Data
Our model "learned" what distracted driving looks like from images obtained from a Kaggle competition sponsored by State Farm Insurance. The goal of the model is to accurately predict unseen images to the following 10 classes:
- 0: safe driving
- 1: texting - right
- 2: talking on the phone - right
- 3: texting - left
- 4: talking on the phone - left
- 5: operating the radio
- 6: drinking
- 7: reaching behind
- 8: hair and makeup
- 9: talking to passenger
Model
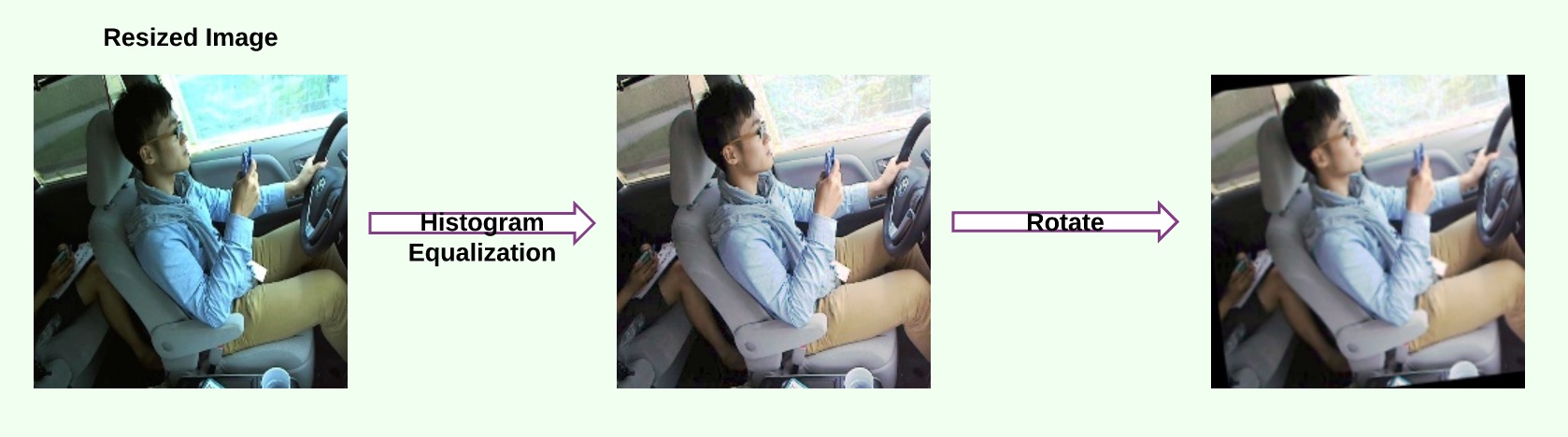
Our initial approach involved training a CNN from "scratch" but we quickly realised that using a pre-trained network might be a better option due to our limited dataset. To be exact, we utilized a technique known as transfer learning where a pre-trained network is used for initialization weights and then further trained to learn the idiosyncrasies of our data. The well-known VGG-16 pre-trained net was used as our starting point. In our VGG-16 net model, we perform global average pooling (GAP) just before the final output layer at the end. This helps the convolutional neural network to have localization ability despite being trained on images.
Class Activation Maps for Different Classes
A class activation map for a particular category indicates the discriminative image regions used by the CNN to identify that category. Below are the class activation maps for safe driving and texting using right hand. For a single class itself based on the position different regions in the image get activated.





Model Accuracy
The training data did not generalize well as the images were captured in a simulated environment. "Real" images showed much more variation in lighting, driver actions, and clarity. In many images, even a human would have difficulty classifying the image due to ambiguity.
Below is the confusion matrix for a subset of test data. The accuracy of the model for this subset of test data was 56.29%. The model finds it difficult to differentiate between the safe driving, talking to passenger, and hair & makeup classes.
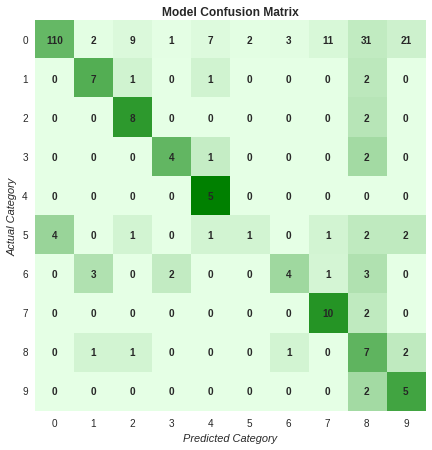
- 0: safe driving
- 1: texting - right
- 2: talking on the phone - right
- 3: texting - left
- 4: talking on the phone - left
- 5: operating the radio
- 6: drinking
- 7: reaching behind
- 8: hair and makeup
- 9: talking to passenger
Analyze
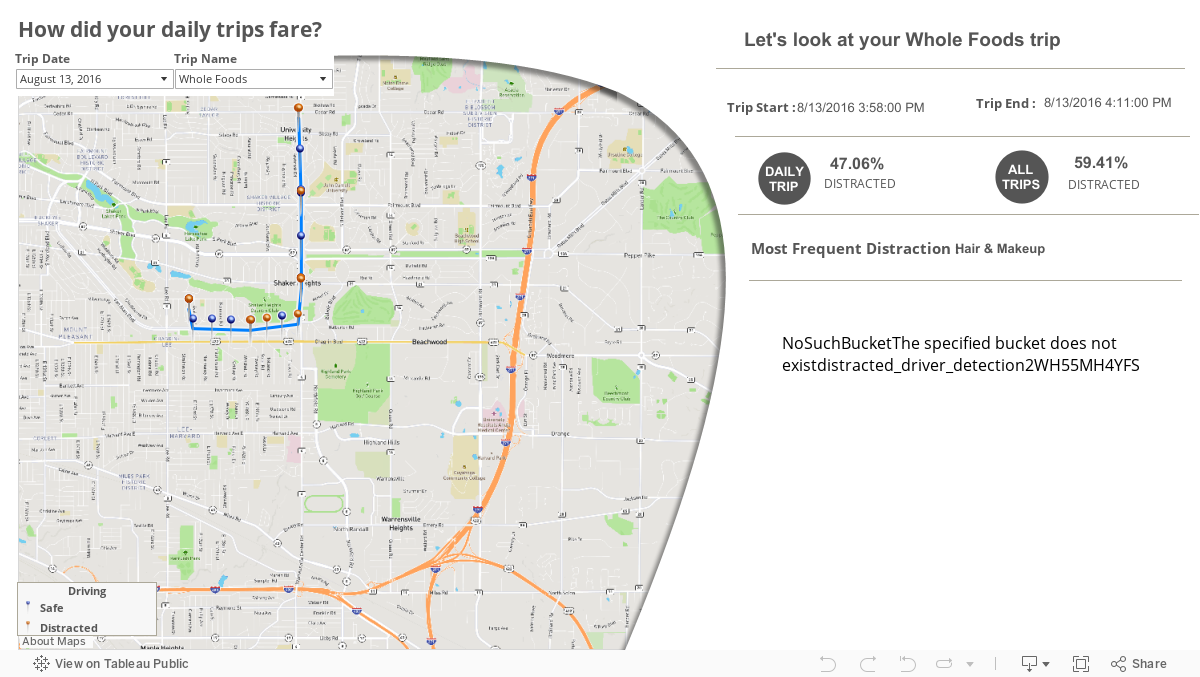
Aggregated View of All Trips
The map below depicts areas where the model detected distracted driving.
Areas with higher frequencies of distraction are colored red.
Detailed View of Trips